Fixed Python autocomplete
Backstory
This story begins with me opening vscode with a python file and seeing this autocomplete:
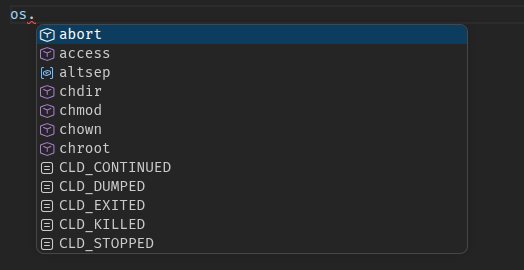
I was in the middle of building a simple text editor,and I thought how could vscode,the most popular code editor in the world, be so unoptimized for programmers?
The autocomplete results were filled with functions I used at most once in my life, with some, like CLD_CONTINUED nowhere to be found, even on the entire public github.
Switching to ty LSP (fastest,open source LSP) from pylance just highlights the problem (basedpyright didnt solve it either).
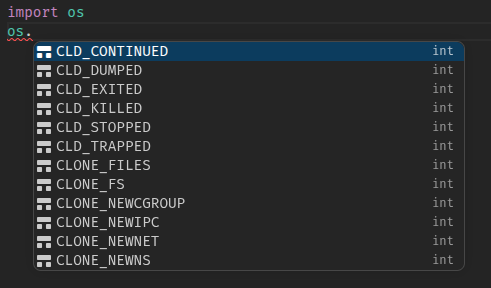 .
.
The problem with alphabet sort for code
In many cases,alphabet order is good. For UI, it looks good.. right?
-
Google Material - “Lists should be sorted in logical ways that make content easy to scan, such as alphabetical,..,or by user preference”
-
uxcel - “Can be alphabetical, numerical, or custom”
-
Apple HIG - “Place items to convey their relative importance”
-
NN/g - “..,prioritization by importance or frequency are usually better than A-Z listings..,People Rarely Think A–Z”
In programming, you type letter by letter, when you write sys.a you are (almost) certainly not thinking about sys.abiflags or sys.activate_stack_trampoline
Solutions
Some IDEs, like PyCharm, offer an AI-based autocomplete, this is usually very good autocomplete. However, it’s slow, and usually off by default. When you type code you don’t want your editor to run a full AI model (or even slower, a full LLM) for every letter you type.
Instead of training an AI to detect the rules of autocomplete so it could work with any module, all I actually needed was a simple table of most used functions/attrs for most common modules, which is going to account for most of the code anyway.
So, I used an existing python dataset, called ManyTypes4PyDataset,v1.7 which contains 5.2K Python repositories, and I built a simple python script to count all calls to builtin functions or attributes that happened more than once. That results in a table like this one
| prefix | score |
|---|---|
| os.stat | 1459 |
| os.environ | 8317 |
..~100,000 rows
However, just dumping this table would result in a big and slow file for no reason, so I designed a binary to make it faster. The Focus: lookup speed.
Hash Score Table format
The first thing that takes up space here is the prefix string. Since the format is designed to be query only, no need to include the actual string (instead,it includes just the hash). The format uses a fast hash, FNV-1a , shifted to be 24-bit.
- Header (magic `HSCT`+version) - 8 bytes
- capacity and slot count - 8 bytes
- Slots hash table 4 bytes repeated:
- Hash key (FNV-1a >> 8) - 3 bytes
- frequency - 1 byte
(Using powers of 2 to avoid % operation on lookup)
The frequency is normalized into 1-255 range, so it can be stored with 1 byte.
By this point, I abandoned my python script, and migrated it to go (partly using an LLM, they are trained on go), as python was good as a prototype, but it was too slow to iterate every time on the 5k json files.
Thresholds
Following the steps above gives a ~4.4Mb file, mostly full of things like myClass.A(),that are too specific. creating a classical name filter (A.A) only changes the file size to a ~4.2Mb file.
I added two new thresholds.
- Filter by total number of calls (or accesses). For example, if
os.statwas called 1459 times, it’s probably because it’s popular (raw) - Filter by number of projects calling. For example, if a function is called 1500 times only by a single project, it is probably not popular (proj)
These two thresholds very quickly changed the file size, as you can see in the interactive. Important calls/attr dropped appear below.
UPDATE:
Using path filtering and a bit of over elimination (only considering unique paths), I got the project threshold to work better, and so reduce the size of p=3 r=2 by 3/4
—
Result
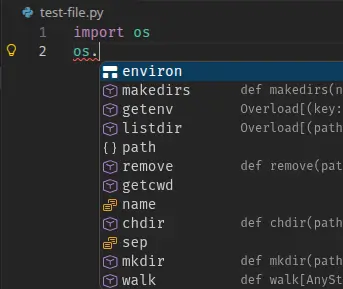
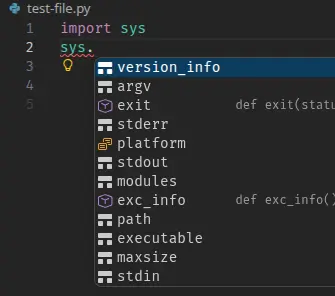
os. autocomplete. On the right, sys. autocomplete
There are many ways to use this table, you can look at the pyhash repo. I published prebuilt datasets in releases.
My ty fork includes a table (raw threshold 7), hopefully it will be merged to ty sometime. In the meantime, you can build it and use it manually
This was one of the most interesting projects I’ve done. Looking at vscode from the viewpoint of a new editor developer presented the opportunity to do this.
“In all affairs, it’s a healthy thing now and then to hang a question mark on the things you have long taken for granted” ~ Russell
Comments: (You can also Comment directly to this discussions )