I analyzed stackoverflow
backstory
I read hackernews sometimes, and articles like I mirrored all the code from PyPI to GitHub and analysed it made me think, maybe there are less obvious places with leaked information.
This was in the back of my mind until recently, when I tried to contribute to the buildozer project. I implemented rich logs, and I felt like I understood buildozer, so I searched for stackoverflow questions about it. Then I discovered that buildozer, unlike beeware , actually dumps the full environment when a command fails (for example output, see this old question), and thought “what if this user built the app with a sensitive api ?”
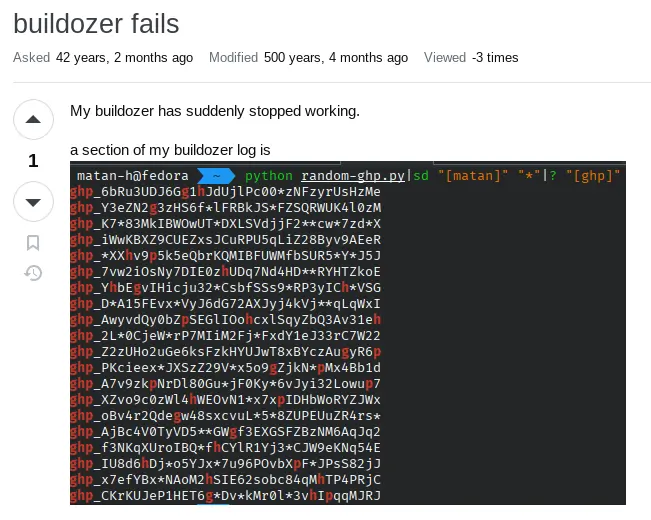
parsing
So, I downloaded stackOverflow from the stackexchange archive.org dump, and started to think how to parse it. It’s a huge (103G) XML file, where each line is a question or answer.
I tried different “leak detect” tools, most of them crashed or taking too much cpu:
-
gitleaks :
fatal error: runtime: out of memory(Update: After I posted this article, @zricethezav from GitHub made a gitleaks PR to fix this, and now (v8.18.1) it does not crash.) -
truffleHog : Actually works (and takes 100% cpu), but giving very poor results (e.g. a simple
%sis considered a SQL server base64 encoded:Detector Type: SQLServer,Decoder Type: BASE64,Raw result: %s). -
ripsecrets : no output 1 hour after I run it.
-
(Yelp) detect-secrets:
Traceback (most recent call last): ... MemoryError -
ripgrep : freeze my system after few minutes.
So I ended up returning to my zsh and doing grep , and even writing a my own rust script to do the searches.
results
As I suspected , there are a lot of leaks in stackoverflow (on the graph, only unique and not junk data is displayed. click on a label to hide it ):
As you can see, a lot of data.
Then, I asked myself, what could an attacker do with this information? Turns out, most of it is useless:
For using most data, you need more information than just the api key. For example, for stripe , you need the customer ID. For grafana, an instance url. For aws, a site url.
And even if you have an api key which goes to a centralized location without need for a “username”, most of the data is old. All the JWTs (JSON Web Tokens) - forget about them, the average life of a JWT is a month.
Until I run a simple scan (again using the best hacking tools : xargs and curl ) against all the 74 real looking GitHub user tokens (which is a token that grants access to pretty much the full GitHub user) and discovered that 6 of them are actually valid.
Still, only 2 of them actually have bio and email, but one of them (a c/c++ developer) has a repo with 3.4k stars. So I finally found the path an attacker would take.
I sent both developers an email (I told them about this research and referred them to the question where they leak the token, with a little “if you find this message helpful, you can buy me a coffee” at the end) and they both revoked the tokens (and both actually bought me a coffee, the first time I got money since I opened this buymeacoffee account in March 2021!).
I obviously couldn’t verify all the secrets. From most of them I’ll probably be banned, so I stooped here.
cause
Unlike PyPi and GitHub leaks articles, this article is not because of people leaving the password in their deploy-to-server.py and accidentally committing it (well, sometimes they copy deploy-to-server-example.py into stackoverflow and forget to mask the id …).
Most leaks are in the output of tools, a long output that people like to copy/paste right into stackoverflow, without actually looking at it, because of people publish the output/ the tool config file of the tool they using (e.g. did you know that curl -v also displays your request with the headers, or that a long package.json with private dependencies can contain git+your-private-gh-token ? )
I hope you enjoyed the article, and pay more attention to what you copy/paste in StackOverflow.
Comments: (You can also Comment directly to this discussions )